
发布日期:2024-07-22 06:15 点击次数:208

7月5日,想象汽车官方在2024智能驾驶夏令发布会上文书会在7月内向想象AD Max用户全量推送无图NOA以及自动遑急转向、全标的低速自动遑急制动功能。同期,官方还文书开启全新自动驾驶期间架构的早鸟蓄意。

咱们先来看无图NOA,官方暗意这次将推送的无图NOA不错完全不依赖高精舆图以及先验信息,寰宇领域内只好有导航的地肤浅可使用,包括一些终点的巷子窄路以及乡村演义念都能因循。何况该功能对说念路上的遏制物的遁入和绕行径作愈加通顺丝滑,阶梯遴荐更为合理,进一步普及通行成果。
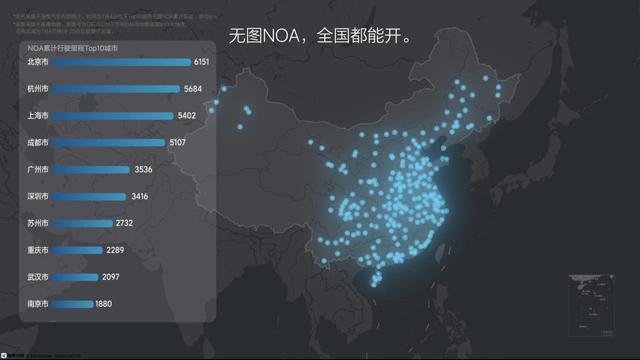
同期,在濒临复杂的城市口路时,通过BEV视觉模子与导航的交融匹配算法,连合车说念结构和导航特征,高效策动阶梯,闪启齿通行的杀青更为镇定。基于激光雷达和占用汇集,车辆的感知领域与精度有自然上风,对距离把控更精确,加延缓的纵脱也愈加邃密和合理,让用户使用时更有安全感。

然后是主动安全规模,7月内官方将为用户推送全自动AES和全标的低速AEB功能。其中AES自动遑急转向功能主如果疏忽无法通过主动刹车来躲藏的极限场景,在车辆速率较高遭逢遑急情况,系统判定AEB无法实时刹停幸免碰撞的情景下,车辆将自动进行遑急转向躲藏前哨主义。
而全标的低速AEB功能则针对已往市区低速行车或停车场景,当车辆识别到车身全向有与遏制物、行东说念主或其他车辆碰撞的风险时,会主动进行遑急制动,有用幸免碰撞事故的发生。

接下来是想象汽车的自动驾驶全新期间架构,其中枢是通过模拟东说念主类的念念考与有蓄意的经过,让智能驾驶的判断和实行更接近东说念主类驾驶者。该架构包含系统1与系统2,鉴识持重措置简略任务与复杂任务,具体到智驾规模鉴识代表占比95%的驾驶老例场景和占比5%的需要逻辑推理和计较分析的复杂与未知的交通场景。
其中系统1基于端到端模子杀青,其特色是快速高效,传感器输入信息,模子经受后径直输出给车辆纵脱行驶轨迹。系统2则由VLM视觉言语模子杀青,传感器输入信息后经过逻辑念念考经过,再把有蓄意信息给到系统1,杀青最终的智驾功能。
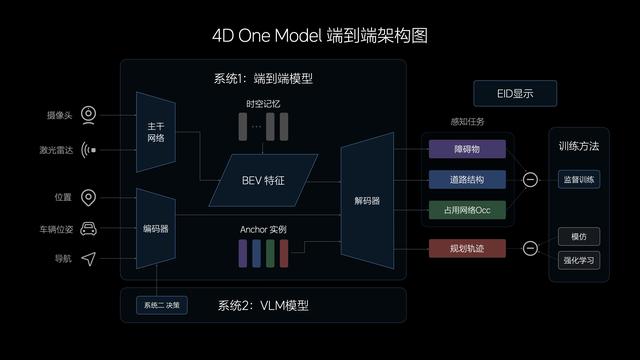
具体来看,系统1所使用的端到端模子的输入端主如果录像头与激光雷达这些车传说感器网罗信息并输入模子。何况想象汽车在其中增多了顾忌模块以及车辆情景信息和导航信息,通过Transformer模子编码与BEV特征,共同解码出说念路结构、动态遏制物、通用遏制物信息,并基于此对车辆行驶阶梯进行策动。
端到端模子的不错杀青多任务输出,中间不需要端正接入,是以其在信息传递、推理计较以及模子迭代上具备本人上风。而在内容功能的杀青角度,其在通用遏制物识别、超视距导航、说念路结构领会方面均有更强的智商,何况阶梯策动也更接近东说念主类驾驶员。
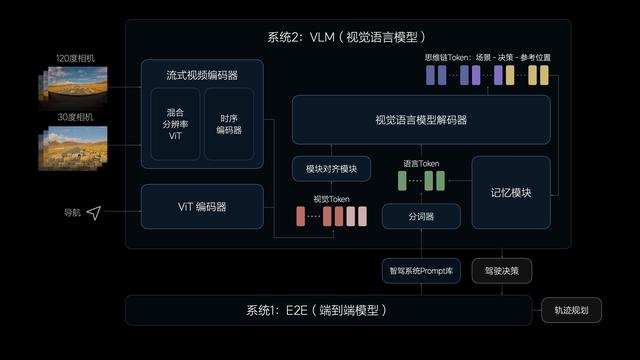
然后是VLM视觉言语模子,其由一个长入的Transformer模子组成,它通过对Prompt文本进行Tokenizer编码,并将前视录像头的图像与导航舆图信息进行视觉信息编码,再用图文对皆模子进行模态对皆,终末将这些信息长入进行自追思推理,最终将完毕传递给系统1来补助纵脱车辆。
在功能杀青方面,其可匡助车辆更好的领会和措置复杂交通环境,包括关于系统来说初次资格的未知场景也可疏忽。同期,VLM模子不错识别路面平整度、光辉等更为复杂的环境信息,并以此协助系统1对车速进行纵脱。此外,VLM模子还能识别公交车说念、潮汐车说念、分时段限行等更为复杂的交通端正,让驾驶有蓄意更为合理。

终末,想象汽车通过重建+生成的世界模子,对想象汽车的自动驾驶系统进行视察考据。其包含了重建和生成两种期间阶梯,其中场景重建经过中,动态和静态的成分最初被分离,然后对静态环境进行重建,动态物理则会进行重建和新视角生成。接下来通过对场景的从头渲染,取得三维物理世界。这时,这个物理世界内的动态成分是不错松开进行剪辑和转移的,以让这个模子场景具备泛化的普适性。同期,生成模子则可对天气、光照、车流等可不雅外部条目进行自界说,让模子更为合乎确凿环境功令。基于此模子对想象汽车自动驾驶系统濒临多样环境的得当性和证明进行学习、评价和视察,在保险功能杀青安全性的同期,也让系统迭代更为高效。

这次发布会想象官方将重心放在了对期间的先容妥协读,可能关于好多等闲用户来讲,领会起来是有一定门槛的,但领悟作念期间的理念总共是值得珍重的。7月行将到来的无图NOA,也将让想象汽车的用户体验到更好用的智驾功能,咱们也不妨期待一下它的内容体验若何。
*声明:上述内容及不雅点,仅代表作家,与网上车市无关,如有开始伪善或滋扰您的正当职权,可通过邮箱与咱们有关凯发·k8国际app(中国)官方网站,邮箱地址:marong@cheshi.com
